Golang八股笔记
概述
数据类型
字符串相关
翻转含有中文、数字、英文字母的字符串
来源链接:GolangFamily
题目: 翻转含有中文、数字、英文字母的字符串,如翻转下面的字符串:你好abc啊哈哈。
回答:
这个问题其实本质上是在讨论Golang中的字符串的原理了,以下论述基本来源于Go 101 。
在Go语言里面,所有字符串常量(string constants)都是以UTF-8编码的,在编译期,非法的编码会导致编译错误,但是这种检查不会在运行期进行检查。对于UTF-8比编码来说,每个代码点(code point)被存储为1-4个字节,例如英语字母使用1个字节来存储,中文汉字使用4个字节存储。且代码点在Go语言中使用rune这个类型来表示的,它是int32的别名。所以实际上来说,对于这个题目,我们只需要将string转换为[]rune就可以实现对它的翻转了。
|
|
切片
基本原理
扩容
当大于扩容后的时,如果小于1024时,预估容量是扩容前容量的2倍
当大于扩容后的时,如果大于1024时,预估容量是扩容前容量的1.25倍,即以0.25增加
array和slice的区别
回答:
数组定长,定义的时候就需要确定。切片长度不定,append时会自动扩容
相同大小数组可以赋值,会拷贝全部内容。slice赋值和指针一样。数组和slice之间不能相互赋值。当然slice有自己的copy函数
数组也可以进行切片,返回值是一个slice,改变slice时会同步修改数组内容,相当于取得了这个数组的指针
拷贝大切片一定比小切片代价大么?
来源链接:GolangFamily
回答:
切片的数据结构如下:
|
|
且拷贝切片的本质上就是拷贝这个数据结构,因此大切片与小切片拷贝的代价是一样的。
slice深拷贝和浅拷贝
回答:
slice的浅拷贝就是slice变量赋值操作。
slice的深拷贝就是使用内置的copy函数,拷贝两个slice。
map
基本原理
对应map的源码可以在
src/runtime/map.go中找到。
map底层的哈希表通过与运算的方式选择桶(bucket),其本质是一个hmap类型的指针:
|
|
map底层的哈希表通过与运算的方式选择桶,所以hmap中并不直接记录桶的个数,而是记录这个数目是2的多少次幂。
map每个桶里可以存储8个键值对,并且为了内存使用更加紧凑,8个键放一起,8个值放一起。对应每个key只保存其哈希值的高8位(tophash)。而每个键值对的tophash、key和value的索引顺序一一对应。这就是map使用的桶的内存布局。

为了减少扩容次数,这里引入了溢出桶(overflow)。溢出桶的内存布局与之前介绍的常规桶相同。如果哈希表要分配的桶的数目大于$2^4$,就会预分配$2^{(B-4)}$个溢出桶备用。这些常规桶和溢出桶在内存中是连续的,只是前$2^B$个用作常规桶,后面的用作溢出桶。
扩容
map的扩容有两种情况,如果超过负载因子(默认6.5)就触发翻倍扩容 ,如果没有超过设置的负载因子上限,但是使用的溢出桶较多,则触发等量扩容 。
翻倍扩容
翻倍扩容分配新桶数目是旧桶的2倍,hmap.oldbuckets指向旧桶,hmap.buckets指向新桶。hmap.nevacuate为0,表示接下来要迁移编号为0的旧桶。
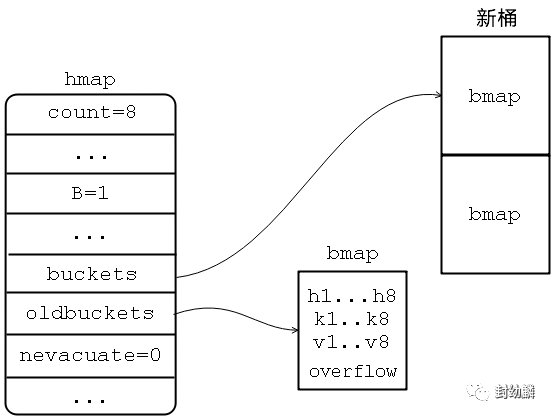
然后就是通过渐进式扩容的方式,每次读写map时检测到当前map处在扩容阶段hmap.oldbuckets != nil,就执行一次迁移工作,把编号为hmap.nevacuate的旧桶迁移到新桶,每个旧桶的键值对都会分流到两个新桶中,这是一个数学问题。
等量扩容
等量扩容,就是创建和旧桶数目一样多的新桶,然后把原来的键值对迁移到新桶中。我们可以考虑什么情况下,桶的负载因子没有超过上限值,却偏偏使用了很多溢出桶呢?自然是有很多键值对被删除的情况。
map不初始化使用会怎么样
回答:
回答参考了部分Go maps in action 上的内容。
|
|
map类型是引用类型(Reference type),就类似指针pointers或切片slices
,因此上面的m的值为 nil;它不指向初始化的map。一个map若为nil,则在读取时表现得像一个空映射,但尝试写入一个为nil的map会导致运行时恐慌。
|
|
map不初始化长度和初始化长度的区别
回答:
回答参考了以下的资料:
|
|
第一种形式创建一个新的map,它分配有足够的空间来容纳至少n个条目,而无需再次重新分配内存。
第二种形式只接受一个参数,在这种情况下,一个新的空映射具有足够的空间来容纳少量条目而无需再次重新分配内存。具体条目的数字取决于编译器。
map承载多大,大了怎么办
回答:
承载多大可以查看:map不初始化长度和初始化长度的区别 这个问题,这个问题告诉我们有关承载的问题。
而后续大了怎么办,主要是通过扩容来处理,主要有两种方式实现扩容:
map的iterator是否安全?能不能一边delete一边遍历?
回答:安全,可以。
普通map如何不用锁解决协程安全问题
参考链接:CSDN博客
回答:
- 读写锁
sync.Mapatomic.Value- channel
map如何顺序读取
回答:通过正常的iterator进行的遍历是不能实现顺序读取的,因此若想实现顺序读取,则需要先对key进行排序,然后在通过对应的key去进行遍历。
进阶
优化相关
内存逃逸相关
参考以下文章
golang程序变量会携带有一组校验数据,用来证明它的整个生命周期是否在运行时完全可知。如果变量通过了这些校验,它就可以在栈上分配。否则就说它逃逸了,必须在堆上分配。
能引起变量逃逸到堆上的典型情况:
- 在方法内把局部变量指针返回。局部变量原本应该在栈中分配,在栈中回收。但是由于返回时被外部引用,因此其生命周期大于栈,则溢出。
- 发送指针或带有指针的值到channel中。 在编译时,是没有办法知道哪个goroutine会在channel上接收数据。所以编译器没法知道变量什么时候才会被释放。
- 在一个切片上存储指针或带指针的值。 一个典型的例子就是
[]*string。这会导致切片的内容逃逸。尽管其后面的数组可能是在栈上分配的,但其引用的值一定是在堆上。 - slice的背后数组被重新分配了,因为append时可能会超出其容量(cap)。slice初始化的地方在编译时是可以知道的,它最开始会在栈上分配。如果切片背后的存储要基于运行时的数据进行扩充,就会在堆上分配。
- 在interface类型上调用方法。 在interface类型上调用方法都是动态调度的 —— 方法的真正实现只能在运行时知道。想像一个
io.Reader类型的变量r, 调用r.Read(b)会使得r的值和切片b的背后存储都逃逸掉,所以会在堆上分配。
我们可以通过go build -gcflags=-m来查看逃逸情况:
|
|
执行go build -gcflags=-m main.go查看内存逃逸情况:
|
|
并发编程
sync.Map相关内容
参考以下文献:
sync.Map类似于Go的map[interface{}]interface{},但可以安全地被多个goroutine并发使用,而无需额外的锁定或协调。加载、存储和删除以摊销的常数时间运行。
sync.Map类型针对两种常见用例进行了优化
- 当给定键的条目只被写入一次但读取多次时,如在只会增长的缓存中,
- 当多个goroutine读取、写入和读取时覆盖不相交的键集的条目。
在这两种情况下,与使用单独的 Mutex或 RWMutex配对的 Gomap相比,使用sync.Map 可以显著减少锁争用。
orcaman/concurrent-map的适用场景是:反复插入与读取新值,其实现思路是:对go原生map进行分片加锁,降低锁粒度,从而达到最少的锁等待时间(锁冲突)。
请你说说golang的CSP思想
参考链接:
CSP的是Communicating Sequential Processes(CSP)的缩写,翻译成中文是顺序通信进程。其核心思想为:
Do not communicate by sharing memory; instead, share memory by communicating. 不要以共享内存的方式来通信,而是要通过通信来共享内存。
channel实现
参考链接:
channel的底层源码和相关实现在src/runtime/chan.go中。
channel是怎么保证线程安全的?